总结摘要
Twitter的存档备份包,我们可以用 grailbird_update 更新备份。只要双击存档备份包里的 index.html 就能够在浏览器里浏览全部推文历史。但是,这个存档浏览可能不是我喜欢的风格,我也不想需要太多元素,我只需要其中一部分内容即可
Twitter的存档备份包,我们可以用 grailbird_update 更新备份(见
利用 grailbird_update 存档备份 Tweets
)。只要双击存档备份包里的 index.html 就能够在浏览器里浏览全部推文历史。但是,这个存档浏览可能不是我喜欢的风格,我也不想需要太多元素,我只需要其中一部分内容即可,这个存档 tweets 里包含的图片还是在 twitter 上存储,我又想下载到本地,我还想在我的博客里展示我一段时间内的 tweets ,…… 这么多需求怎么办?只能定制,于是有了下面我的探索路程:批量导出 Tweets 为指定格式内容,并下载相关图片和视频资源到本地,真正实现个性化、离线化。
备注: 相关文件代码已经存到我的 Github repository :
extract-tweets
。
相关说明
以下是Twitter存档备份包的文件目录结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
Tweets_Litanid /
├── css
│ └── application . min . css
├── data
│ └── js
│ ├── payload_details . js
│ ├── tweet_index . js
│ ├── tweets
│ │ ├── 2014 _10 . js
│ │ ├── 2014 _11 . js
│ │ ├── 2015 _03 . js
│ │ ├── …………………………
│ │ ├── …………………………
│ │ ├── …………………………
│ │ ├── …………………………
│ │ ├── 2018 _02 . js
│ └── user_details . js
├── img
│ ├── bg . png
│ └── sprite . png
├── index . html
├── js
│ ├── application . js
│ └── zh - CN . js
├── lib
│ ├── bootstrap
│ │ ├── bootstrap - dropdown . js
│ │ ├── bootstrap . min . css
│ │ ├── bootstrap - modal . js
│ │ ├── bootstrap - tooltip . js
│ │ ├── bootstrap - transition . js
│ │ ├── glyphicons - halflings . png
│ │ └── glyphicons - halflings - white . png
│ ├── hogan
│ │ └── hogan - 2.0 . 0. min . js
│ ├── jquery
│ │ └── jquery - 1.8 . 3. min . js
│ ├── twt
│ │ ├── sprite . png
│ │ ├── sprite . rtl . png
│ │ ├── twt . all . min . js
│ │ └── twt . min . css
│ └── underscore
│ └── underscore - min . js
├── README . md
├── README . txt
└── tweets . csv
tweets 信息存储有两种格式,一种是 .csv 格式,上述结构目录树中的 tweets.csv 便是,另外一种是 json 格式,上述结构目录树中的 2014_10.js 、 2014_11.js等以年份_月份命名的 .js 文件便是。刚从 Twitter 官方下载的存档包,两种数据格式都包含所有的推文信息(当然不包含图片和视频)。用 grailbird_update 更新存档备份包,不更新 tweets.csv ,只更新 json 数据格式,默认只更新三个文件,一是更新增加修改上述以年份_月份命名的 .js 文件,再就是更新修改 payload_details.js 和 stweet_index.js 文件。
如从 tweets.csv 里提取 tweets 信息,可以参考
Tweet Archive Logger 仓库
, 相关代码见
extract-tweets
下的 tweet_archive_logger_by_liam-m.py 。
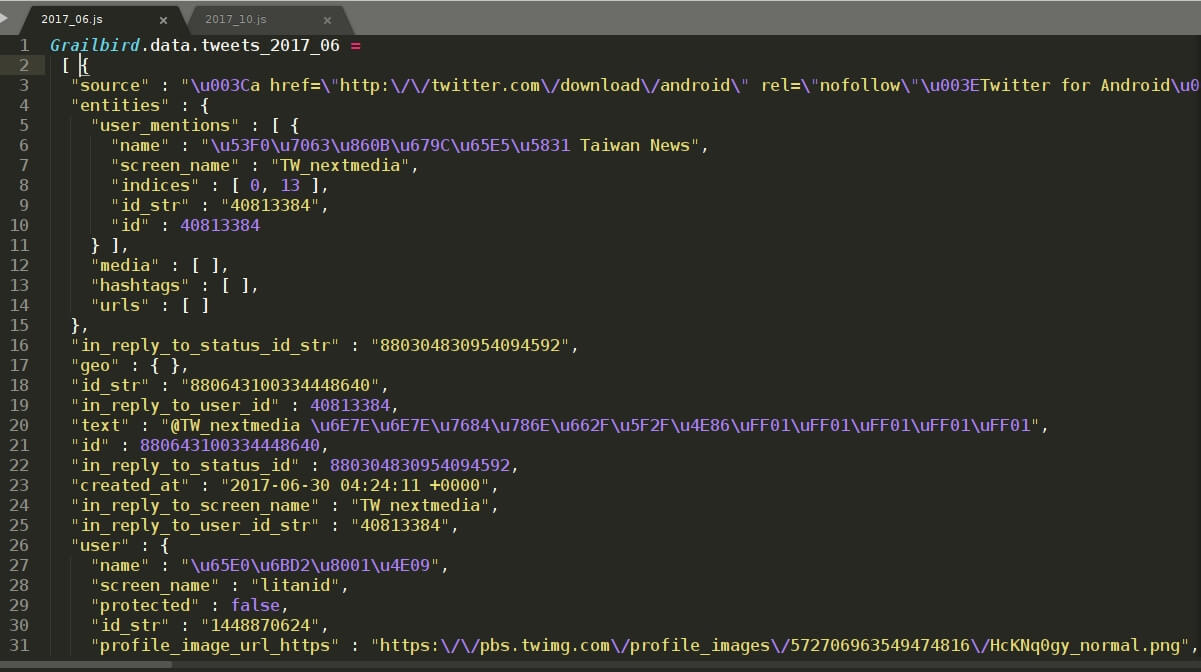
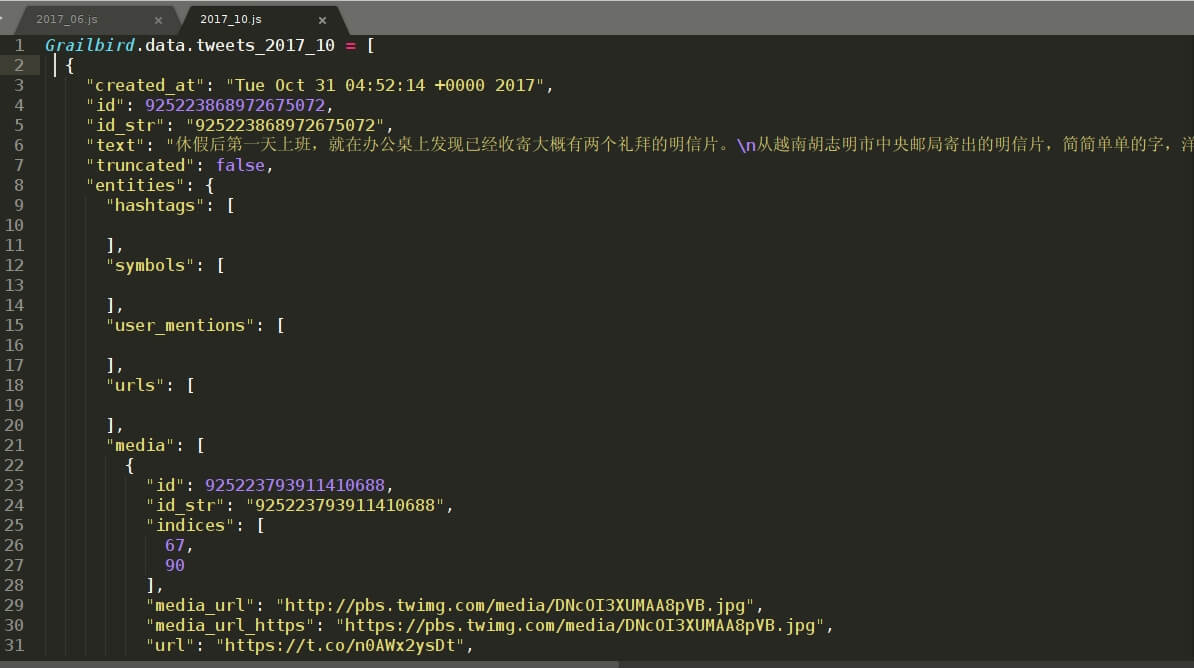
在这里,我们要处理的是以年份_月份命名的 .js文件,如 2014_10.js 、2014_11.js 等,从其中提取 tweets 信息。每个文件包含其中一个月内的全部推文。 .js 文件内 tweet 存储格式以启用 grailbird_update 更新存档备份包时刻为分界点划分为两部分,之前与之后的格式不一样。我是2017年8月24日启用 grailbird_update 更新存档备份包的,所以我的 2017_08.js 文件里包含两种存储格式的 tweets 。之前的我们以 2017_06.js 为例,之后的我们以 2017_10.js 为例。如下图:
区别主要有三点:
1.created_at时间格式不一样, 2017_06.js 里显示的是:2017-06-22 09:31:07 +0000, 2017_10.js 里显示的是:Tue Oct 31 04:52:14 +0000 2017 。
2.text 显示格式不一样, 2017_06.js 显示的是诸如\u8F66\u7EC8…… 的 unicode 编码, 2017_10.js 里直接显示汉字。
3.如果有多于一张图片, 2017_06.js 里所有图片信息在entities -> media 里, 2017_10.js 则是在 extended_entities -> media里。
所以,处理 tweets 信息代码也是有针对性的区分。
我的 Github repository :
extract-tweets
里代码文件 extract-tweets_by_DrDrang.py 是 Dr. Drang 在博文
Completing my Twitter archive
里的代码。代码文件 twitter-export-image-fill_by_MarcinWichary.py 是 mwichary 在他的 Github repository:
twitter-export-image-fill
里的代码。我改写完善的文件 extract-tweets-to-md_by_litanid_after.py 和 extract-tweets-to-md_by_litanid_before.py 主要是参考借鉴这两篇文章。带 before 的是针对启用 grailbird_update 更新前存档备份包的 json 文件。此处主要介绍说明 extract-tweets-to-md_by_litanid_after.py 代码文件,以 2017_10.js 作处理示例。
代码按 Python3 要求编写,Python2 需要少许更改。
1
2
3
4
5
6
7
8
9
10
11
from datetime import datetime , timezone , timedelta
import sys
import re
import json
import os
import termios #实现按任意键退出
if ( sys . version_info & gt ; ( 3 , 0 )):
from urllib.request import urlretrieve
else :
from urllib import urlretrieve
导入相关库。
1
2
#instrp = '%Y-%m-%d %H:%M:%S +0000' #对应如 2017-12-31 15:15:15 +0000
instrp = ' %a %b %d %H:%M:%S +0000 %Y' #对应如 Wed Nov 29 15:37:26 +0000 2017
按照 2017_10.js 文件里 tweets 的 created_at 显示时间设置相应格式
1
2
3
4
outstrf = '%Y-%m- %d %H:%M:%S CST UTC+08:00'
urlprefix = 'https://twitter.com/litanid/status/'
outputFile_extension = '.md'
images_vedio_urlprefix = 'https://pich.yiwan.org/YiWan/TwitterPictures/'
相应输出,设置输出为北京时间、每条 tweet 链接地址的前缀、输出文件的扩展名、下载的多媒体文件链接地址前缀(即下载的图片和视频保存的服务器目录)。
1
2
3
4
5
6
7
for month_tweets_filename in sys . argv [ 1 :]:
#取得输出文件的文件名和扩展名
outputFile_name = '' #清空重置文件名
outputFile_name = os . path . basename ( month_tweets_filename )
outputFile_name_temp = outputFile_name
outputFile_name = os . path . splitext ( outputFile_name )[ 0 ]
outputFile_name = outputFile_name + outputFile_extension
输入命令执行处理时,可以一次性输入好几个 .js 文件。获取输入的 .js 文件名,如 2017_10.js ,得到 2017_10.md 的输出文件名。
1
2
3
4
5
6
7
with open ( month_tweets_filename ) as data_file :
data_str = data_file . read ()
first_data_line = re . match ( r 'Grailbird.data.tweets_(.*) =' , data_str ) . group ( 0 )
data_str = re . sub ( first_data_line , '' , data_str )
data_tweets = json . loads ( data_str )
data_tweets . reverse ()
读取每一个要处理的 .js文件内容,去除首行的 Grailbird.data.tweets_2017_10 = ,并将 tweets 反转,按照时间由前至后。
1
2
3
4
5
6
7
8
9
10
for tweet in data_tweets :
#处理日期时间显示格式,原时间格式为格林尼治时间,转为北京东八区时间
created_at = tweet [ 'created_at' ]
dt = datetime . strptime ( created_at , instrp )
dt = dt . replace ( tzinfo = timezone . utc )
tzutc_8 = timezone ( timedelta ( hours = 8 ))
local_dt = dt . astimezone ( tzutc_8 )
local_dt = local_dt . strftime ( outstrf )
local_datetime = local_dt [: 19 ]
datetime_number = re . sub ( r '(\d+)-(\d+)-(\d+) (\d+):(\d+):(\d+)' , r '\1\2\3\4\5\6' , local_datetime )
读入每一条 tweet 内容,将 tweet 时间转为北京时间。
1
2
3
4
5
6
7
8
9
10
try :
if tweet [ 'entities' ][ 'urls' ]:
for replaceurl in tweet [ 'entities' ][ 'urls' ]:
url = replaceurl [ 'url' ]
expanded_url = replaceurl [ 'expanded_url' ]
display_url = replaceurl [ 'display_url' ]
display_url = "<a href='" + expanded_url + "' target= \" _blank \" >" + display_url + "</a>"
tweet_text = re . sub ( url , display_url , tweet_text )
except KeyError :
pass
将 tweet['text']里包含的网址 url 转为原先内容,twitter 默认将它转为系统短链。
1
2
3
media_directory_name = datetime_number [: 6 ]
if not os . path . isdir ( media_directory_name ):
os . mkdir ( media_directory_name )
建立以年月为名称的文件夹用来保存当月的图片和视频。
1
2
3
4
5
6
7
if 'extended_entities' in tweet . keys () and 'media' in tweet [ 'extended_entities' ] . keys ():
medialist . extend ( tweet [ 'extended_entities' ][ 'media' ])
if 'retweeted_status' in tweet . keys () and 'extended_entities' in tweet [ 'retweeted_status' ] . keys () \
and 'media' in tweet [ 'retweeted_status' ][ 'extended_entities' ] . keys ():
medialist . extend ( tweet [ 'retweeted_status' ][ 'extended_entities' ][ 'media' ])
medialist = list ( dedupe ( medialist , key = lambda d : d [ 'media_url_https' ]))
tweet 文里包含的图片和视频信息存在 tweet['extended_entities']['media']或者tweet['retweeted_status']['extended_entities']['media']里,if 依次判断是否存在这个主键,保险起见将tweet['extended_entities']['media']和tweet['retweeted_status']['extended_entities']['media']内容合并在一起,去除重复内容,得到最终的 medialist 列表,每一个列表元素代表一个多媒体。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
for media in medialist :
if media [ 'type' ] == "photo" :
media_url_https = media [ 'media_url_https' ]
media_filename = os . path . basename ( media_url_https )
# Download the original/best image size, rather than the default one
better_media_url_https = media_url_https + ':orig'
local_media_filename = ' %s / %s X %s%s H %s ' % \
( media_directory_name , datetime_number , tweet [ 'id' ], tweet_image_count + 1 , media_filename )
if os . path . isfile ( local_media_filename ):
print ( " \t *********已经下载过这张图片 {0} ,此处略过!" . format ( media_url_https ))
local_media_filename = images_vedio_urlprefix + local_media_filename
print ( "<br /><a href=' {0} '><img class='alignnone size-medium' src=' {1} ' /></a>" . format ( local_media_filename , local_media_filename ), file = outputFile )
tweet_image_count = tweet_image_count + 1
tweet_image_total_count = tweet_image_total_count + 1
else :
print ( " \t *********下载第 {0} 张图片: {1} " . format ( tweet_image_count + 1 , media_url_https ))
try :
urlretrieve ( better_media_url_https , local_media_filename )
except :
print ( " \t *********第 {0} 张图片( {1} )下载失败!!" . format ( tweet_image_count + 1 , media_url_https ))
tweet_image_failure_count = tweet_image_failure_count + 1
pass
else :
local_media_filename = images_vedio_urlprefix + local_media_filename
print ( "<br /><a href=' {0} '><img class='alignnone size-medium' src=' {1} ' /></a>" . format ( local_media_filename , local_media_filename ), file = outputFile )
tweet_image_count = tweet_image_count + 1
tweet_image_total_count = tweet_image_total_count + 1
print ( " \t *********第 {0} 张图片( {1} )下载成功!!" . format ( tweet_image_count , media_url_https ))
读入 medialist 列表每一个元素,判断多媒体是图片还是视频,下载到同目录的以 tweet 发布时间年月命名的文件夹下(此文件夹最终要拷贝到图片服务器相应目录),同时设置图片显示代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
elif media [ 'type' ] == "video" :
media_image_url_https = media [ 'media_url_https' ]
media_image_filename = os . path . basename ( media_image_url_https )
# Download the original/best image size, rather than the default one
better_media_image_url_https = media_image_url_https + ':orig'
local_media_image_filename = ' %s / %s X %s%s H %s ' % \
( media_directory_name , datetime_number , tweet [ 'id' ], tweet_image_count + 1 , media_image_filename )
if os . path . isfile ( local_media_image_filename ):
print ( " \t *********已经下载过这张视频封面图 {0} ,此处略过!" . format ( media_image_url_https ))
local_media_image_filename = images_vedio_urlprefix + local_media_image_filename
tweet_image_count = tweet_image_count + 1
tweet_image_total_count = tweet_image_total_count + 1
else :
print ( " \t *********下载第 {0} 张图片: {1} " . format ( tweet_image_count + 1 , media_image_url_https ))
try :
urlretrieve ( better_media_image_url_https , local_media_image_filename )
except :
print ( " \t *********第 {0} 张图片( {1} )下载失败!!" . format ( tweet_image_count + 1 , media_image_url_https ))
tweet_image_failure_count = tweet_image_failure_count + 1
pass
else :
local_media_image_filename = images_vedio_urlprefix + local_media_image_filename
tweet_image_count = tweet_image_count + 1
tweet_image_total_count = tweet_image_total_count + 1
print ( " \t *********第 {0} 张图片( {1} )下载成功!!" . format ( tweet_image_count , media_image_url_https ))
video_quality_temp = []
for video_quality in media [ 'video_info' ][ 'variants' ] :
if "bitrate" in video_quality :
video_quality_temp . append ( video_quality )
else :
continue
aftersorted_video_quality = sorted ( video_quality_temp , key = lambda quality : quality [ 'bitrate' ], reverse = True )
better_media_video_url_https = aftersorted_video_quality [ 0 ][ 'url' ]
better_media_video_filename = os . path . basename ( better_media_video_url_https )
local_media_video_filename = ' %s / %s X %s%s H %s ' % \
( media_directory_name , datetime_number , tweet [ 'id' ], tweet_video_count + 1 , better_media_video_filename )
if os . path . isfile ( local_media_video_filename ):
print ( " \t *********已经下载过这个视频 {0} ,此处略过!" . format ( better_media_video_url_https ))
local_media_video_filename = images_vedio_urlprefix + local_media_video_filename
tweet_video_count = tweet_video_count + 1
tweet_video_total_count = tweet_video_total_count + 1
print ( " \n <video src=' {0} ' controls autoplay loop> Your browser does not support the <code>video</code> element.</video> \n " \
. format ( local_media_video_filename ), file = outputFile )
else :
print ( " \t *********下载第 {0} 个视频: {1} " . format ( tweet_video_count + 1 , better_media_video_url_https ))
try :
urlretrieve ( better_media_video_url_https , local_media_video_filename )
except :
print ( " \t *********第 {0} 个视频( {1} )下载失败!!" . format ( tweet_video_count + 1 , better_media_video_url_https ))
tweet_video_failure_count = tweet_video_failure_count + 1
pass
else :
print ( " \t *********第 {0} 个视频( {1} )下载成功!!" . format ( tweet_video_count + 1 , better_media_video_url_https ))
local_media_video_filename = images_vedio_urlprefix + local_media_video_filename
tweet_video_count = tweet_video_count + 1
tweet_video_total_count = tweet_video_total_count + 1
print ( " \n <video src=' {0} ' controls autoplay loop> Your browser does not support the <code>video</code> element.</video> \n " \
. format ( local_media_video_filename ), file = outputFile )
如果是视频,则首先下载视频封面。视频地址保存在media['video_info']['variants']中,有几种码率,选择分辨率最高的。再下载视频文件,设置视频显示代码。
1
2
3
4
5
6
7
8
print ( "<br /><a href=' {0} ' target= \" _blank \" > {1} </a>" . format ( tweetlink_url , local_dt ), file = outputFile )
print ( "---" , file = outputFile )
print ( "---------------------------------------" )
print ( " \n ##############" )
print ( " \n 本次归档共计成功下载 {0} 张图片、 {1} 个视频,下载失败 {2} 张图片、 {3} 个视频!" . \
format ( tweet_image_total_count , tweet_video_total_count , tweet_image_failure_count , tweet_video_failure_count ))
print ( " \n ##############" )
print ( " \n ====================文件 {0} 处理完毕==================== \n " . format ( outputFile_name_temp ))
每条 tweet 时间下链接设置为 tweet 链接地址,一个 .js 文件处理完毕显示下载了多少张图片和几个视频。
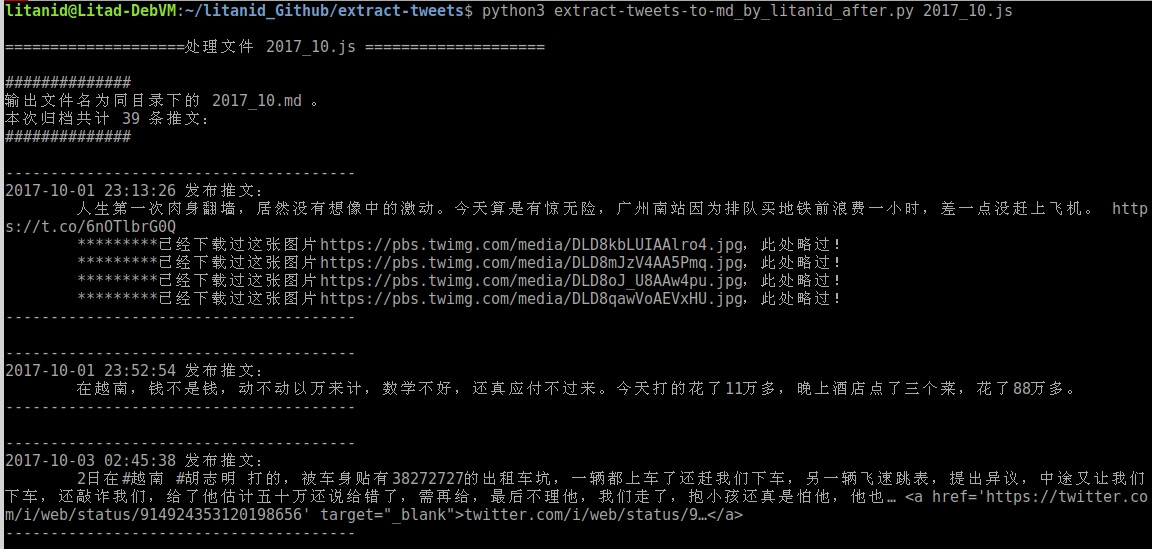
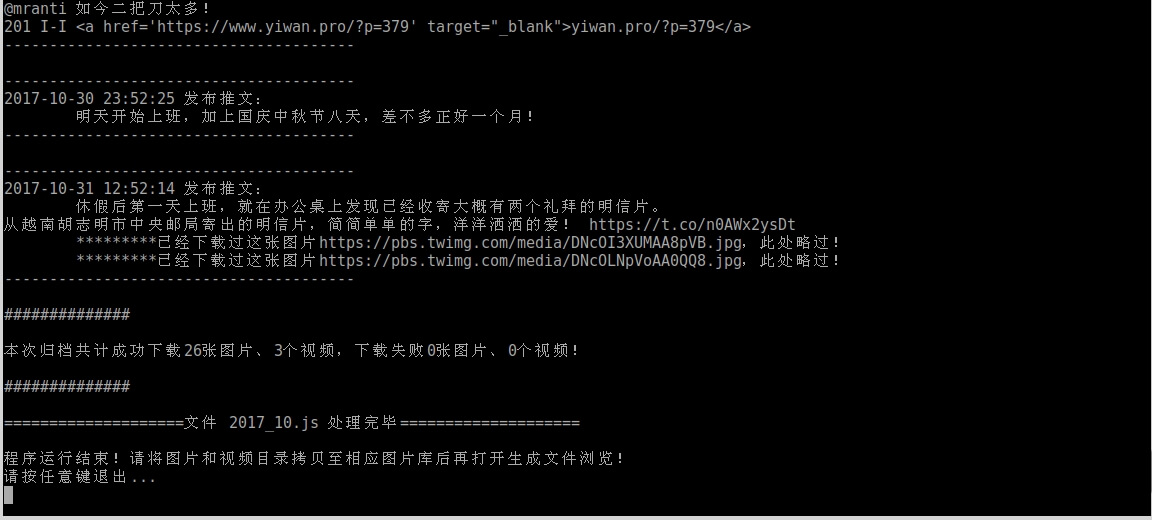
运行显示
用 python3 运行 extract-tweets-to-md_by_litanid_after.py 后面跟随放置在同目录下的 2017_10.js 文件(可以多个文件),运行结果显示如下:
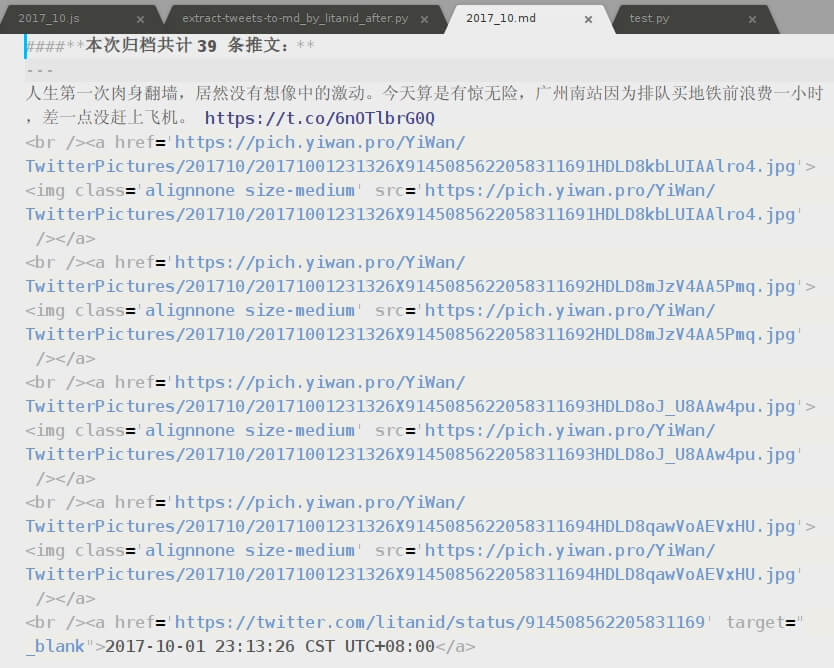
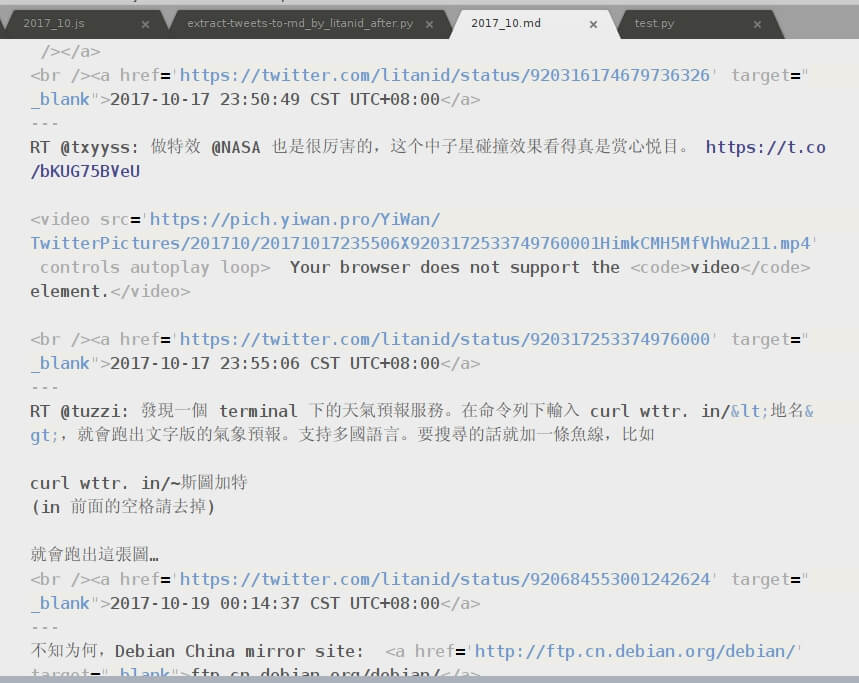
生成同目录下的 2017_10.md文件,内容如下:
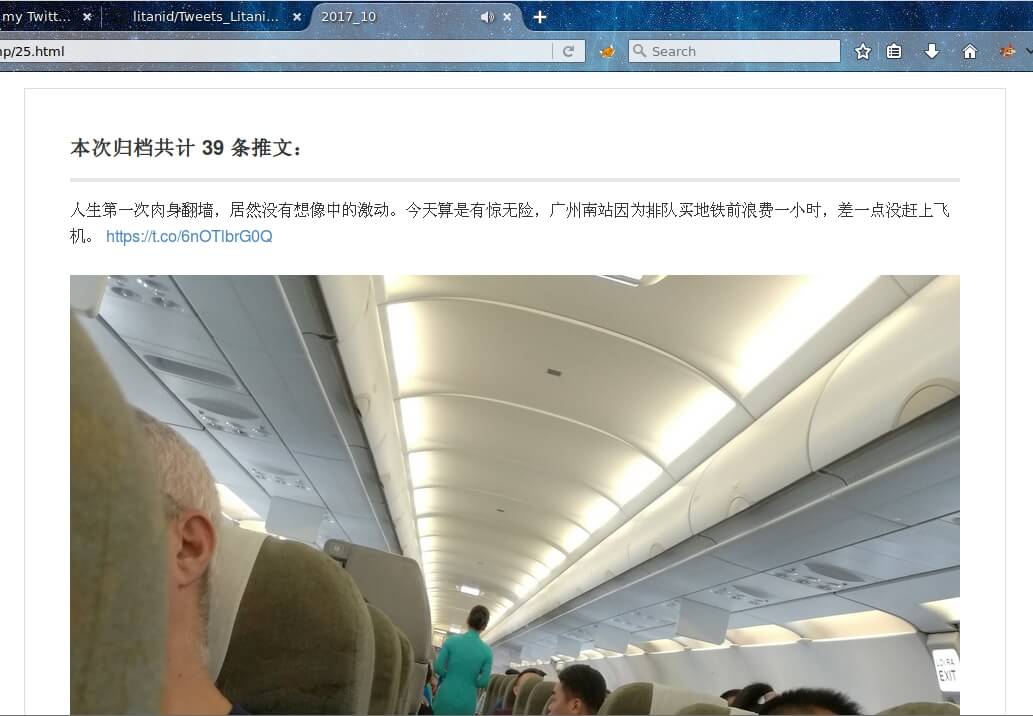
将生成的同目录下的201710文件夹拷贝到服务器目录 https://pich.yiwan.org/YiWan/TwitterPictures/ 下,再在浏览器预览 2017_10.md 文件,结果显示如下:
至此处理完毕。输出 Markdown 文件,当然也可以按自己需求输出为其他格式文件。 extract-tweets-to-wp_by_litanid_after.py 文件运行输出结果可以直接贴到 wordpress 文章代码编辑窗口里,此处不述,详情请看代码。